- Info@SaminRay.Com
- 88866172 021
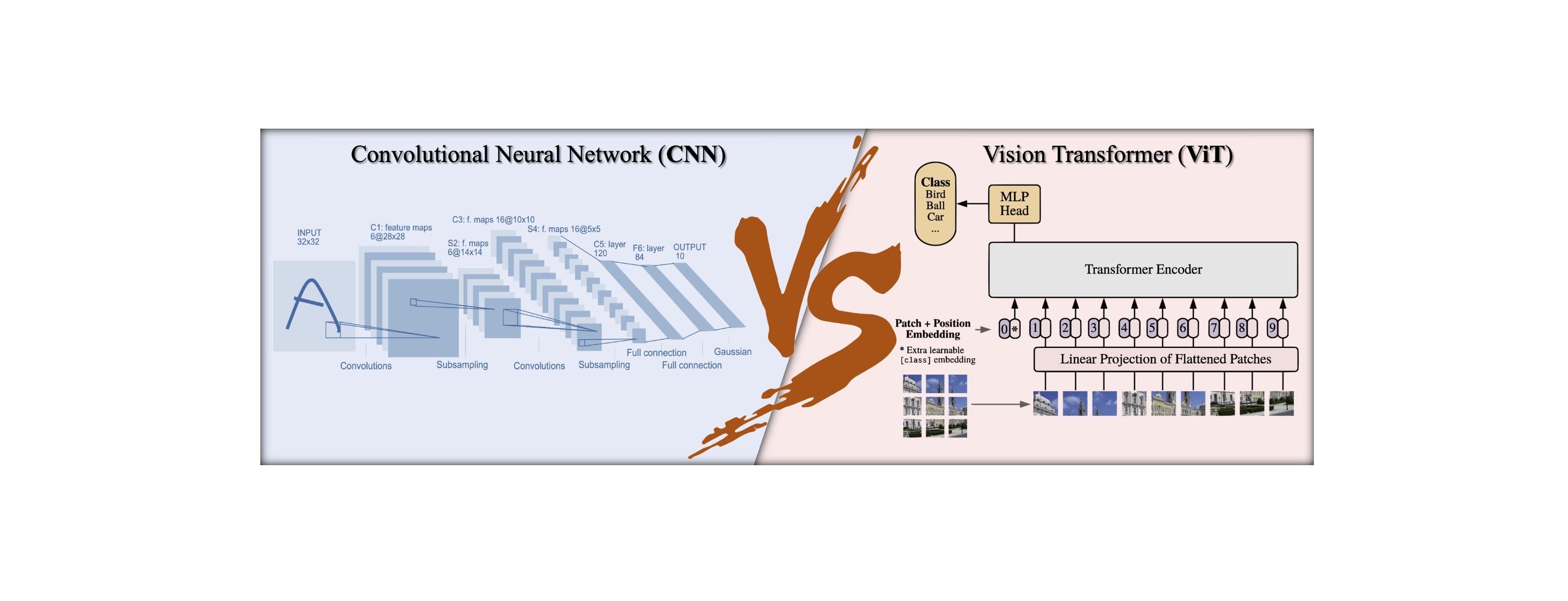
مقایسه شبکه عصبی کانولوشنی و ترانسفورمرهای بینایی
در طی دهه گذشته، سیستمهای تشخیص تصویر به طور قابل ملاحظهای تکامل یافتهاند. در ابتدا، محققان برای تشخیص و طبقهبندی اشیا در تصاویر از ویژگیهای دستساز و الگوریتمهای یادگیری ماشین استفاده میکردند.
در طی دهه گذشته، سیستمهای تشخیص تصویر به طور قابل ملاحظهای تکامل یافتهاند. در ابتدا، محققان برای تشخیص و طبقهبندی اشیا در تصاویر از ویژگیهای دستساز و الگوریتمهای یادگیری ماشین استفاده میکردند. اما معرفی یادگیری عمیق و شبکههای عصبی پیچشی (CNNs)، این حوزه را به طور کامل تغییر داد و امکان تشخیص دقیق و کارآمدتر اشیا را فراهم ساخت. مدتهاست که CNNها به عنوان یک مدل مرسوم برای وظایف تشخیص تصویر استفاده میشوند، اما اخیراً، ترانسفورمر بینایی (ViT) به عنوان یک رقیب جدید مطرح شده است. ترنسفورمرها ابتدا برای پردازش زبان طبیعی طراحی شده بودند، اما با گذر زمان ViTها با استفاده از مکانیزمهای خودتوجه و رمزگذاری اطلاعات مکانی که پیشتر در ترنسفورمرها استفاده میشد، توانایی قابل توجه ای از خود در خاتمه دادن به سلطه شبکه های CNN در مسایل بینایی ماشین از خود نشان دادند.
شبکه عصبی کانولوشنی
شبکههای عصبی پیچشی یا به اصطلاح CNNها یک دسته از مدلهای یادگیری عمیق هستند که به طور خاص برای پردازش و تجزیه و تحلیل دادههای شبکهای مانند تصاویر طراحی شدهاند. با الهام گرفتن از سیستم بینایی انسان، CNNها به دلیل توانایی یادگیری خودکار ویژگیهای معنادار از دادههای خام پیکسلی، سنگ بنای وظایف بینایی ماشین شدهاند. معماری یک CNN معمولی شامل سه لایه اصلی است: لایههای پیچشی، لایههای پولینگ و لایههای کاملاً متصل. این لایهها به صورت ترکیبهای مختلف پشت سر هم قرار میگیرند تا شبکههای عمیق و پیچیدهای ایجاد شود که قادر به یادگیری نمایشهای سلسله مراتبی از دادههای بصری باشند. برخی از معماریهای محبوب CNN که تأثیر قابل توجهی در حوزه تشخیص تصویر داشتهاند عبارتند از:
LeNet-5: که توسط یان لیکان و همکارانش در دهه 1990 توسعه داده شده است، یکی از اولین CNNها است. در ابتدا برای تشخیص اعداد دستنویس طراحی شده بود و پایه ای برای معماریهای آینده CNN قرار گرفت.
AlexNet: که توسط الکس کریژوفسکی، ایلیا ساتسکور و جفری هینتون در سال 2012 پیشنهاد شد، در چالش تشخیص بصری مقیاس بزرگ (ILSVRC) پیشرفت قابل توجهی را به دست آورد و به طرز چشمگیری از روشهای سنتی عبور کرد. این معماری استفاده از CNNهای عمیقتر و بزرگتر را برای وظایف تشخیص تصویر معرفی کرد.
VGG: که توسط گروه هندسه تصویری در دانشگاه آکسفورد در سال 2014 توسعه داده شد، نشان داد که استفاده از شبکههای عمیقتر با فیلترهای کانوولوشنی کوچک (3x3) چه فوایدی دارد. معماری ساده و ماژولار آن باعث شد که در انتقال یادگیری و تنظیم دقیق در برنامههای مختلف محبوب باشد.
ResNet: که توسط کایمینگ هو و همکارانش در سال 2015 معرفی شد، مشکلات ناپدید شدن گرادیان در شبکههای عمیق را از طریق استفاده از اتصالات پرش، که به شبکه اجازه میدهد توابع باقیمانده را یاد بگیرد، رفع کرد. معماری ResNet امکان آموزش شبکههای عمیقتر را فراهم کرد و عملکرد را در بنچمارکهای مختلف بینایی کامپیوتر بهبود چشمگیری بخشید.
DenseNet: که توسط گائو هوانگ و تیمش در سال 2016 پیشنهاد شد، اتصالات متراکم بین لایهها را معرفی کرد که مشکل ناپدید شدن گرادیان را کاهش میدهد و استفاده مجدد از ویژگیها را تشویق میکند. این موضوع منجر به مدلهای کوچکتر و کارآمدتر نسبت به CNNهای سنتی شد.
معماریهای فوق، حوزه تحقیقات و کاربردهای بینایی کامپیوتر را شکل دادهاند. آنها قدرت و چندکاره بودن CNNها را نشان داده و راه را برای پیشرفتهای جدید در این حوزه باز کردهاند. اگرچه شبکههای عصبی کانوولوشنی (CNN) در وظایف مختلف بینایی کامپیوتر بسیار موفق بودهاند، اما نقاط ضعف خاصی نیز دارند. برخی از این محدودیتها عبارتند از:
1. نیاز به حجم بالای داده: CNNها برای آموزش به تعداد زیادی از تصاویر نیاز دارند. این موجب میشود که برای آموزش مدلهای بزرگ، منابع سخت افزاری و زمان زیادی مورد نیاز باشد.
2. انتقال یادگیری محدود: CNNها برای یادگیری ویژگیهای مشخص شده در مجموعه داده آموزشی بهتر عمل میکنند. اگر مجموعه داده آموزشی با مسئله واقعی متفاوت باشد، عملکرد آنها ممکن است کاهش یابد.
3. احتمال بالای برازش بیش از حد: CNNها ممکن است در مجموعه داده آموزشی به خوبی عمل کنند، اما در مواردی که با دادههای جدید و ناشناخته روبرو شوند، عملکرد ضعیفی داشته باشند. این پدیده به عنوان برازش بیش از حد (overfitting) شناخته میشود.
4. حساسیت به تغییرات مکانی: CNNها معمولاً به تغییرات مکانی در تصاویر حساس هستند. به عبارت دیگر، اگر یک تصویر به اندازه کوچکی جابجا شود یا چرخانده شود، ممکن است نتیجه تشخیص تغییر کند.
با این حال، با توجه به پیشرفتهای اخیر در حوزه بینایی کامپیوتر و یادگیری عمیق، تلاشهای بسیاری برای مقابله با این محدودیتها و بهبود عملکرد CNNها صورت گرفته است.
ترانسفورمرهای بینایی
ترانسفورمرهای بینایی (ViT) به عنوان یک جایگزین قابل اعتماد برای شبکههای عصبی کانوولوشنی در وظایف بینایی کامپیوتر ظاهر شدهاند. ترانسفورمرهای بینایی معماری ترانسفورمر اصلی را که در ابتدا برای وظایف Seq2Seq در پردازش زبان طبیعی پیشنهاد شده بود، برای پردازش تصاویر به عنوان ورودی به کار میبرند. به جای پردازش تصاویر با عملیات کانوولوشن، تبدیلکنندههای بینایی تصاویر را به عنوان دنبالهای از بستههای بدون همپوشانی میبینند، هر بسته را به یک بردار تبدیل میکنند و رمزگذاری مکانی را برای حفظ اطلاعات فضایی اعمال میکنند. سپس دنباله حاصل از بردارها به لایههای ترانسفورمر وارد میشود که از مکانیزمهای خودتوجه برای مدلسازی وابستگیهای بلندمدت و یادگیری ویژگیهای بصری معنادار استفاده میکنند.
ترانسفورمرهای بینایی چگونه کار میکنند؟
- تقسیم تصویر به پچها: تصویر ورودی به بخشهای غیر همپوشانی تقسیم میشود، معمولاً به اندازههای 16x16 یا 32x32 پیکسل. سپس هر پچ به یک بردار تبدیل میشود.
- Embedding: بردارهای پچ با استفاده از یک ماتریس embedding یادگیرنده به فضای مطلوب بعدی تعبیه میشوند.
- رمزگذاری مکانی: تعبیههای مکانی به بردارهای پچ افزوده میشوند تا اطلاعات فضایی در نظر گرفته شوند و مطمئن شود که مدل ترانسفورمر بتواند بین موقعیتهای مختلف پچ در تصویر تفاوت قائل شود.
- لایههای ترانسفورمر: تعبیههای پچ و مکانی با هم به چندین لایه ترانسفورمر منتقل میشوند. این لایهها شامل مکانیسمهای خودتوجه چند سر و شبکههای عصبی فیدفوروارد هستند که به مدل امکان یادگیری تعاملات پیچیده بین پچها را میدهند.
- خروجی: خروجی نهایی لایههای ترانسفورمر توسط یک کلاسیفایر پردازش میشود، معمولاً یک لایه کامل متصل با یک فعالساز softmax، به منظور تولید پیشبینیهای مورد نظر مانند احتمالات کلاس برای وظایف دستهبندی تصویر.
ترانسفورمرهای بینایی نشان دادهاند که میتوانند در بسیاری از وظایف بینایی ماشین عملکرد بهتری نسبت به شبکههای عصبی کانولوشنال سنتی داشته باشند و یک پارادایم جدید برای شناخت بصری ارائه میدهند که از قدرت معماری ترانسفورمر بهره میبرد.
جمع بندی
در طول این مقاله، ما به بررسی تفاوتهای کلیدی بین CNN و ViT از نظر معماری پرداختیم. این مقایسه نقاط قوت و ضعف منحصر به فرد هر دو رویکرد را بیان میکند. ViTها عملکرد برتری را در دقت دستهبندی و استحکام در برخی از سناریوها نشان دادهاند. آنها همچنین ساختارهای نمایش داخلی متمایزی دارند. از سوی دیگر، CNNها ستون فقرات وظایف بینایی ماشین بودهاند و سرعت محاسباتی و سرعت استنتاج سریعتری برای ورودی کوچکتر ارائه میدهند. با این حال، CNNها با چالشهای افزایش اندازه تصاویر با وضوح بالا روبرو هستند و برای آموزش نیاز به حجم زیادی از دادههای برچسبخورده دارند.
در کل، انتخاب بین CNNها و ViTها به نیازهای خاص برنامه و مصالحه بین دقت دستهبندی، استحکام و کارایی محاسباتی بستگی دارد. توجه به این نکته بسیار مهم است که هم CNNها و هم ViTها نقش حیاتی در توسعه برنامههای بینایی ماشینی در آینده ایفا خواهند کرد.